
这是两年前学习Coreseek时在问答区问的一个问题:
当时只是想了下,但没去做,现在学迅搜,又想到这个问题,干脆还是试试把它给做了吧 ^_^
1、数据表字段
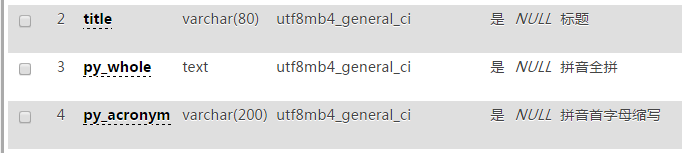
2、ThinkPHP5的model里做 py_whole 和 py_acronym 的自动完成
getAttr('title'); if (empty($title)){ return ''; } // 先对title分词 $xs = new XunSearch('recipe'); $keyword_list = $xs->getScws()->getTokens($title); // 再对title分的每一个词转换成拼音 $pinyin = []; if (count($keyword_list)>0){ foreach ($keyword_list as $keyword){ $keyword_pinyin = gbk_to_pinyin($keyword);// 这里用PHPCMS里般过来的转拼音函数转换 if (is_array($keyword_pinyin) && count($keyword_pinyin)>0){ $pinyin[] = implode ( '' , $keyword_pinyin ); } } } if (count($pinyin)>0){ return implode(' ', $pinyin);// 迅搜里的配置分割方式默认是空格,这里也就用空格了 }else{ return ''; } } // 自动设置拼音首字母缩写 protected function setPyAcronymAttr() { $title = $this->getAttr('title'); if (empty($title)){ return ''; } // 先对title分词 $xs = new XunSearch('recipe'); $keyword_list = $xs->getScws()->getTokens($title); $pinyin = []; if (count($keyword_list)>0){ foreach ($keyword_list as $keyword){ $keyword_arr = mb_str_split($keyword);// 字符进行逐字分割,这是一个自定义函数,解决PHP自带函数不能分割中文问题 // 提取拼音首字母缩写 $keyword_initial = array_map(function( $word ){ $pinyin = gbk_to_pinyin($word); return substr( $pinyin[0], 0, 1 ); }, $keyword_arr); if (is_array($keyword_initial) && count($keyword_initial)>0){ $pinyin[] = implode ( '' , $keyword_initial ); } } } if (count($pinyin)>0){ return implode(' ', $pinyin);// 迅搜里的配置分割方式默认是空格,这里也就用空格了 }else{ return ''; } }} 数据入库时就可以得到这样的结果

3、迅搜的项目配置文件里这样配置
project.name = xxx[id]type = id[title]type = title[py_whole]index = mixedtokenizer = split[py_acronym]index = mixedtokenizer = split
4、测试效果(表中只有30条测试数据,所以结果不多)
public function testxs() { $xs = new \search\XunSearch('recipe'); $keyword = 'mb'; dump('关键词: '.$keyword); $list = $xs->search($keyword, '', 0, 10); dump('查询语句: '.$xs->getQuery()); dump($list); } 
5、用SQL语句验证迅搜的结果与数量对不对
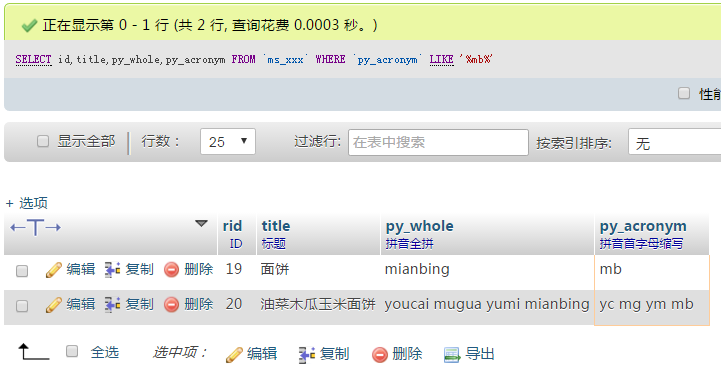
不错,比用迅搜的 getExpandedQuery() 方法转换得到的拼音准确多了